CloudFS - A Cloud-backed File System
- Published on
- • 11 mins read•––– views
This is a course project for (CMU 15-746: Storage Systems)[https://course.ece.cmu.edu/~ece746/]. The project is implemented in C++ and is tested on Ubuntu 18.04 using Amazon EC2.
As per the school's integrity policy, I am not allowed to share any related code publicly. This post serves as a documentation of my design choices and meaningful learnings from the project. With hindsight, I discussed some of the designs that I would have done differently if I were to start over again.
Huge thanks to Prof. Greg and Prof. George for their wonderful lectures.
Introduction
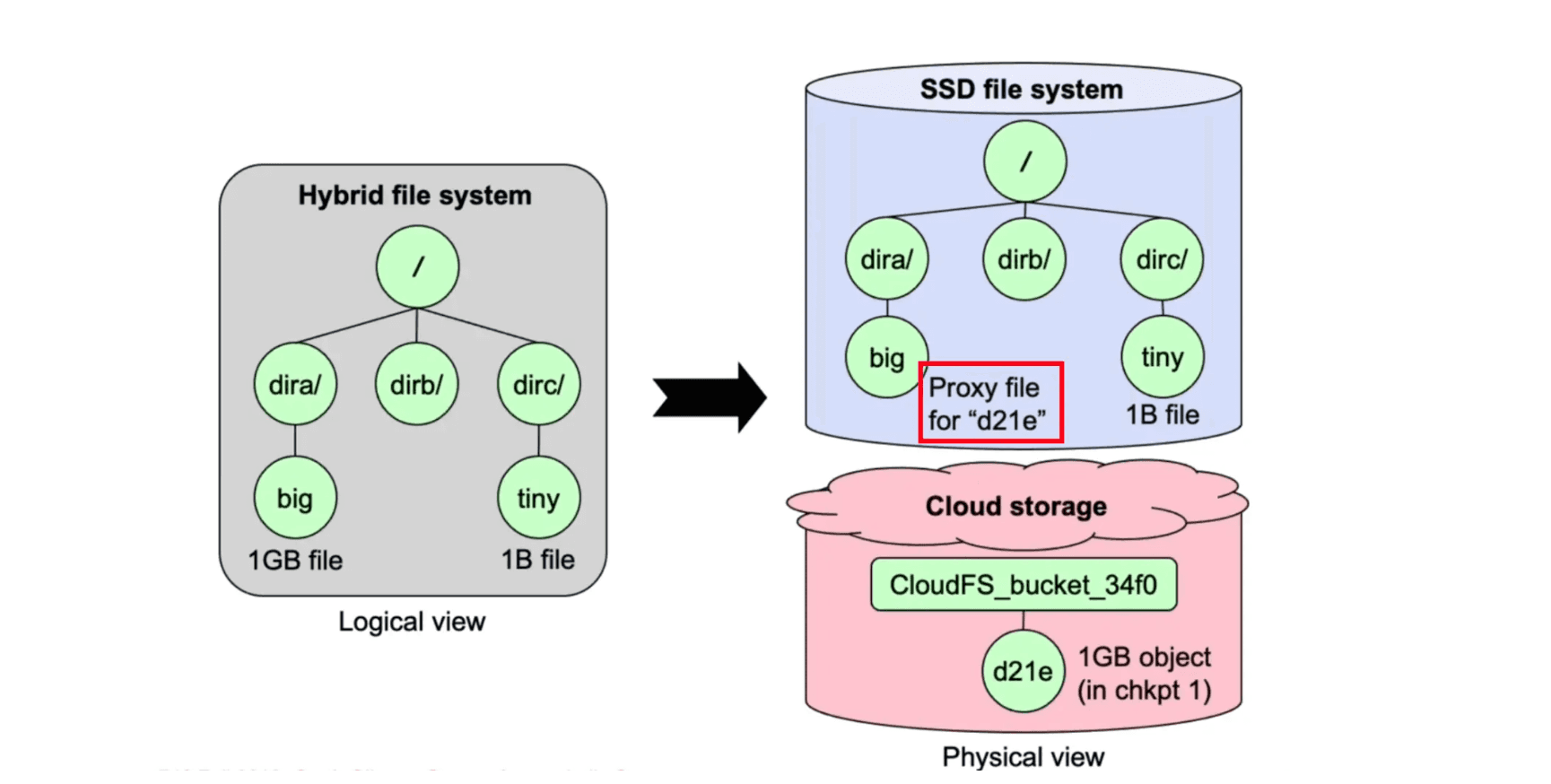
CloudFS is a cloud-backed local file system. Specifically, a CloudFS instance stores all file metadata and files under a predefined file size threshold on a local SSD, and stores the rest of the file data using a cloud storage service from Amazon S3. CloudFS is developed based on the FUSE (Filesystem in USErspace) software interface.
CloudFS consists of four components: a core file system leveraging the properties of local SSD and cloud storage for making data placement decisions; a component that takes advantage of redundancy in data to reduce storage capacity; a component that adds the ability to create, delete, and restore file system snapshots while minimizing cloud storage costs; and a component that uses local on-device and in-memory caching to improve performance and reduce cloud operation costs.
Background
File System and Implementation
In computing, a file system or filesystem (often abbreviated to fs) is a method and data structure that the operating system uses to control how data is stored and retrieved. Without a file system, data placed in a storage medium would be one large body of data with no way to tell where one piece of data stopped and the next began, or where any piece of data was located when it was time to retrieve it. By separating the data into pieces and giving each piece a name, the data are easily isolated and identified. Taking its name from the way a paper-based data management system is named, each group of data is called a "file". The structure and logic rules used to manage the groups of data and their names is called a "file system."
In the perspective of computer architecture, a file system is an abstract layer between the Program Layer and the Device Driver Layer. The Program Layer uses the file system to read/write files, while the Device Driver Layer uses the file system to read/write blocks on the storage device. The file system is responsible for translating the file system operations into block operations.

Because of the great flexibility we have in building a file system, many different ones have been built, literally from AFS (the Andrew File System) to ZFS (Sun’s Zettabyte File System). All of these file systems have different data structures and do some things better or worse than their peers.
As Figure-1 has shown, to implement a file systems, there must be quite a bit operations involving interations with the OS's kernel. One obvious approach is to build an in-kernel file system, which is, obvious complex and error-prone. Luckily, there is a eaisier way for us to do it: FUSE.
Filesystem in Userspace (FUSE) is a software interface for Unix and Unix-like computer operating systems that lets non-privileged users create their own file systems without editing kernel code. This is achieved by running file system code in user space while the FUSE module provides only a bridge to the actual kernel interfaces.

To implement a new file system, a handler program linked to the supplied libfuse library needs to be written. The main purpose of this program is to specify how the file system is to respond to read/write/stat requests. The program is also used to mount the new file system. At the time the file system is mounted, the handler is registered with the kernel. If a user now issues read/write/stat requests for this newly mounted file system, the kernel forwards these IO-requests to the handler and then sends the handler's response back to the user.
FUSE is particularly useful for writing virtual file systems. Unlike traditional file systems that essentially work with data on mass storage, virtual filesystems don't actually store data themselves. They act as a view or translation of an existing file system or storage device.
Cloud Storage Services
Cloud storage is a model of computer data storage in which the digital data is stored in logical pools, said to be on "the cloud". The physical storage spans multiple servers (sometimes in multiple locations), and the physical environment is typically owned and managed by a hosting company. These cloud storage providers are responsible for keeping the data available and accessible, and the physical environment protected and running. People and organizations buy or lease storage capacity from the providers to store user, organization, or application data.
In this project, we'd use Amazon S3 to store the large file data by using simple HTTP APIs.
One thing to note is that unlike with local SSDs, users of cloud storage are billed on a monthly basis. Cloud storage services have different pricing models. For instance, Amazon S3 charges for the capacity of disk space you consume, the amount of data transferred, and each command you submit, e.g. object retrieval operations.
Implementation
There are four main components in CloudFS: a core file system, a component that takes advantage of redundancy in data to reduce storage capacity, a component that adds the ability to create, delete, and restore file system snapshots while minimizing cloud storage costs, and a component that uses local on-device and in-memory caching to improve performance and reduce cloud operation costs.
Core File System
As mentioned above, the core file system is implemented using FUSE. It supports but is not limited to the following operations:
- Take in various command line arguments to configure the file system. E.g., the path to the mount point, the path to the local directory, the path to the cloud directory, the threshold for file size, tuning parameters for the cache & deduplication, etc.
- Support file system operations such as create, delete, and modify files and directories, etc.
- Make file placement decisions based on the file size. Specifically, files smaller than the threshold are stored locally, while files larger than the threshold are stored in the cloud.
Deduplication
Deduplication is a term used when a storage system tries to discover duplication among unrelated files and store duplicate content only once.
The simplest way to think about deduplication is to compute a checksum or hash of the entire file, or perhaps each file block, storing the file’s or block’s hash in a large lookup table. When a new file (or block) is written to the storage system (i.e., added or modified), compute its hash and look up this hash in the lookup table. If the lookup table does not contain the hash, then this data is new, because identical content ensures identical hashes.
If the hashes and data match, the lookup table also provides the location of the stored copy of the data, so you can drop the new copy and use the location of the stored copy in the file (or block) metadata. Storage used in the cloud will now be less than if we had not computed and checked hashes.

Snapshots
Snapshot is an important and useful tool to restore the file system to a previous state, i.e., an earlier point in time. This feature can be used to generate consistent CloudFS backups which come in handy when we need to undo a mistakenly deleted or corrupted file, and when we need to restore the file system on a new SSD after a device failure.

The snapshot() function. This function call will create a tar file to archive current local small files, proxy files and metadata. The cloud reference count will record the reference contribution of this snapshot, and then add the snapshot's reference count to the global reference count table.
The restore(t) function. This function takes in a timestamp of one existing snapshot, it removes every file (excluding some special ones used for implementation purpose) on disk, then download the snapshot file and extract it and the state is restored. An important point here is that after CloudFS is restored to a certain snapshot, all snapshots taken after that one will be invalidated. CloudFS can figure out what changes of the reference count have been made by looking up the global reference count table mentioned above. It will undo those changes by decreasing the global reference count accordingly.
The delete(t) function. This function will delete a snapshot stored on the cloud. Global chunk reference count table will be modified and chunks with zero reference count after deletion will be deleted from cloud to save the cost.
The install(t) function. This function will mount the selected snapshot to a predefined path, letting the user to browse the files within the snapshot. At the implementation level, when installing a snapshot, CloudFS will read the file to chunks mapping table stored in that snapshot, and add a new key value pair into a snapshot mapping table, where the key is the snapshot’s timestamp, and the value is the file to chunks mapping of that snapshot. As such, reads to any snapshot will consult its own name space in the snapshot mapping table and fetch needed file chunks accordingly. This enables multiple installations of snapshot. Each installed snapshot will not interfere each other.
The uninstall(t) function. This function will perfrom reverse operations as opposed to install(t). Specifically, it will remove its namespace from the snapshot mapping table as discussed above. Specifically, the snapshot component of CloudFS saves cloud costs in a twofold manner. First, the snapshot files are compiled into archive files for transmission. This saves the cloud request cost and can pack small IOs into a big one, increasing the write and read performance of the system. Second, since CloudFS tracks the reference count for each chunk, it can save the cloud storage cost by deleting chunks with zero reference count resulted from the restore() or the delete() operation.
Another thought on this snapshot component is that we can also maintain a “cache” on the server side and delay the deletion of chunks whose reference count hit zero. If future local operations create chunks that are present in the server “cache”, we can save the transmission cost since there’s no need to upload again. To avoid storage cost overhead, we can set a time-to-live counter for each chunk in the server cache and set a reasonable cache size.

Caching
A cache manager with configurable caching strategies is implemented in CloudFS. Caching the file chunks locally can greatly reduce the cloud storage / request costs. Here’s the file read and write workflows with caching enabled in CloudFS.


The cloud cost is saved mainly in two ways by the cache component of CloudFS. The first one is, when a large file is being segmented, the chunks are stored in local cache first. Thus, in scenarios that the working set size is close to the cache size, a fairly high cache hit rate can be achieved: following reads and writes are very likely to benefit from a cache hit, and few communications and transmissions between the local machine and the cloud will occur. CloudFS obtains a cache stress test score of 32 on Autolab. The cache hit rates at this moment are decent, but the cloud transmission costs are high. Further improvements still need to be done.
Refs
- Wikipedia: File system
- MLA Style. Arpaci-Dusseau, Remzi H., Arpaci-Dusseau, Andrea C.. Operating systems: three easy pieces. : Arpaci-Dusseau Books, 2014. E-Book.