RexFS, a Raft-Based Distributed File System
- Published on
- • 16 mins read•––– views
This is a course project for (CMU 15-618: Storage Systems)[https://course.ece.cmu.edu/~ece746/].
Introduction
In the modern era of computing, the ability to distribute and manage files across multiple machines in a fault-tolerant manner is crucial. The Distributed File System (DFS) we have developed harnesses this principle to offer a robust and efficient solution.
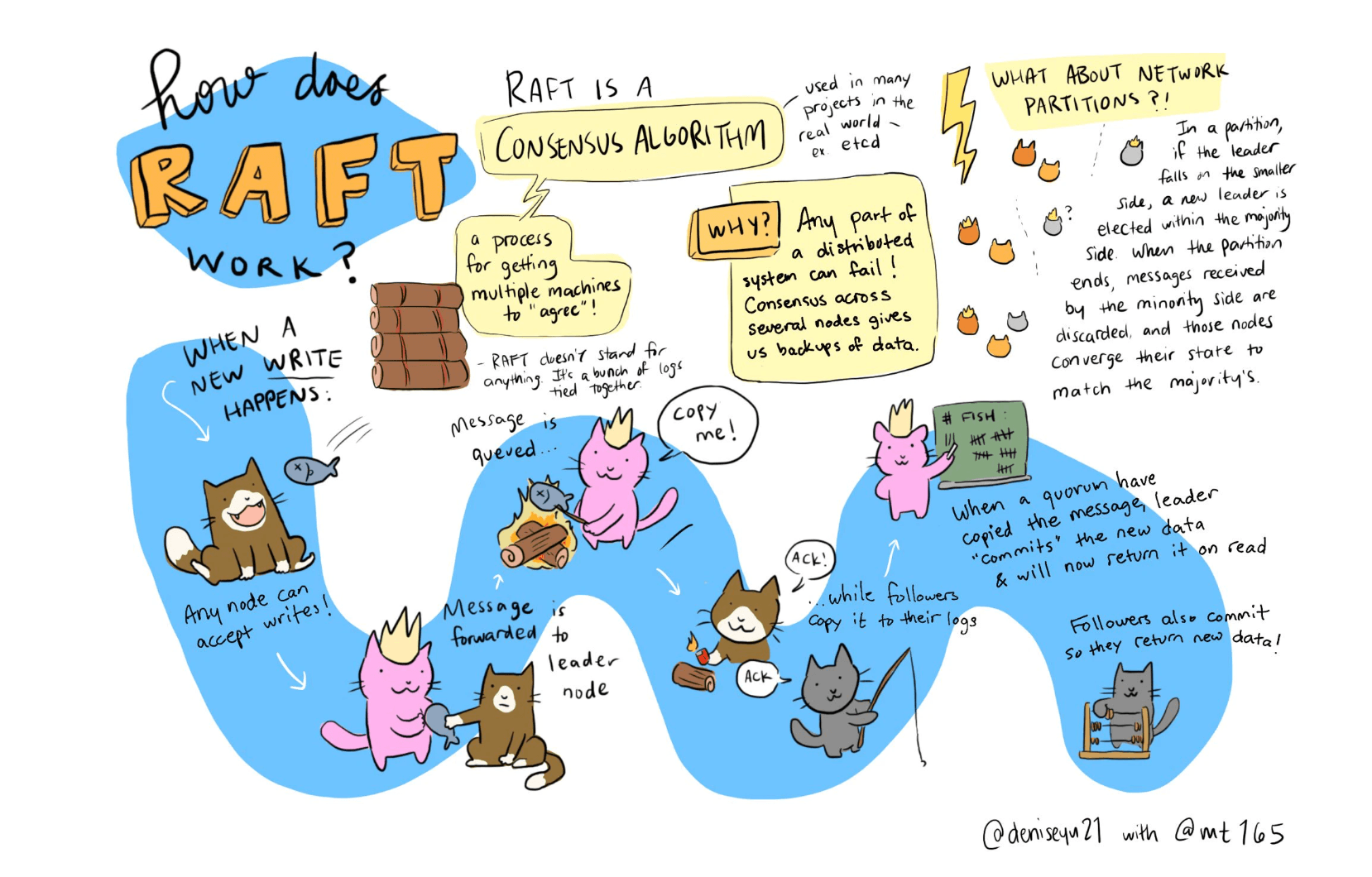
This project is based on the Raft consensus algorithm, a key player in managing replication in distributed systems. Raft was selected for its strong guarantees in terms of safety and its simplified approach as compared to other algorithms like Paxos. Implemented in the robust and versatile Java programming language, our system leverages the strength of object-oriented design, concurrent processing, and vast standard libraries to provide an efficient, scalable, and highly accessible distributed file system.
The core functionalities of our DFS include: storing files, reading files, and writing files to the system, in a way that is agnostic to the user about the underlying complexities of distributed file management. All interactions with the system are handled transparently, making the use of our distributed file system as intuitive as a local file system.
Our implementation of the Raft algorithm ensures that our system maintains consistency across all nodes in the distributed network. This means that even in the event of partial network failures, our DFS will still deliver correct results.
In conclusion, our Distributed File System project aims to present a robust, efficient, and user-friendly solution to managing and manipulating files across a distributed network of machines. Using the power of Java and the reliability of the Raft consensus algorithm, we believe we have created a system that will meet the needs of many users in diverse fields and varying scale of applications.

Design
The interactions between clients and the various server components in our DFS design will closely follow the illustration in Figure 2. Servers and clients will communicate details of files by referring to them by their path, which is a string that uniquely identifies a (potentially replicated) file or directory in the file system. Clients are primarily interested in reading and writing file/directory contents, and storage servers are primarily interested in maintaining these resources and providing access to clients. In our design, storage servers are also responsible for managing file metadata, such as the file size. Storage servers must also respond to commands from the naming server.

In many practical DFS designs, clients do not have direct access to storage servers; instead their view of the file system is the single naming server, which abstracts away many of the other system details, requiring clients to only keep track of a single server address. The naming server tracks the file system's directory structure and maintains a listing of which servers maintain primary or secondary replicas of each listed file. When a client wishes to perform an operation on a file, they contact the naming server to do so. In our model, the naming server will reply providing the IP address and service port number of the storage server hosting the desired file; the client then directly interacts with the storage server at this address. Finally, our naming server provides an interface for new storage servers to register their participation in the file system.
Paths
As stated above, paths are represented by strings, which are transmitted through all interfaces in the file system. Notationally, a path string will take the form /directory/directory2/.../dir-or-filename, where we can utilize Tries as the primary data structure to implement this module. Paths are always taken to be relative to the root / of the file system, and we'll need to make sure that paths can be compared to each other.
Storage Servers
A storage server provides two interfaces: a client interface and a command interface. The client interface is used for interactions between clients and storage servers for the purpose of performing file operations. This API provides the client with three operations: file reading, file writing, and file size query. The command interface is used for interactions between the naming server and the storage servers for the purpose of management. This interface allows the naming server to request that a file on the storage server be created, deleted, or copied from another server as part of replication. The job of the storage server is simply to respond to these requests, which may arrive concurrently. Additional documentation about both client and command interfaces can be found in the starter code repository.
In our DFS design, a storage server is required to keep all its files in local storage on the machine it is running on. The structure of local file storage should match the storage server's view of the structure of the entire file system. For example, if storage server k is storing files locally in /var/storagek as the root directory and hosting a file with path /directory/README.txt, then the file's full path on the local machine would be /var/storagek/directory/README.txt. If a storage server is not aware of the existence of a file in the file system (because it is stored elsewhere), it should not have anything stored locally at that path. This file naming and storage scheme provides a convenient way for data to persist across storage server restarts.
Naming Server
The naming server can be thought of as an object containing a data structure which represents the current state of the file system directory tree and a set of operations that can be performed on the object. It also provide two interfaces: the service interface and the registration interface. The service interface allows a client to create, list, and delete directories; create and delete files; determine whether a path refers to a valid directory or file; obtain the IP address and client port for storage servers; and allow clients to lock and unlock files and directories. The registration interface is used by storage servers to inform the naming server of their presence and intention to join the file system. The registration interface is used once by each storage server on startup. When a storage server is started, it contacts the naming server and provides its IP address and port numbers to be used for its client and command interfaces. The naming server will later share the client port number with clients to serve their requests, and it will later use the command interface to maintain the consistency of the storage server's state. During registration, the storage server also shares a listing of all files that are present in its directory on its local file system. If any of these files are not present in the naming server's DFS object, they are added. If the storage server indicates the presence of any files that the naming server does not want the storage server to maintain, the naming server will request that the storage server delete them.
The naming server transparently performs replication of commonly accessed files, causing multiple storage servers to maintain copies of the same file. This is not under the direct control of the client. The details are given in the section on replication.
Communications
One of the first aspects of the file system that we'll need to create is the ability for naming servers, storage servers, and clients to communicate with each other. Rather than building this using our remote library from previous labs, we're going to do this using HTTP-based RESTful APIsLinks to an external site.. Every component of our system provides a uniform interface, which is fundamental to the design of any RESTful system. It simplifies and decouples the architecture, enabling each component to evolve independently. Individual resources are identified in requests by using commands in RESTful web services. The resources themselves are conceptually separate from the representations that are returned to the client. Our APIs all exchange commands, responses, and data in JSON format.
Coherence and Thread Safety
Each server in the file system must individually be thread-safe, meaning it should be able to perform actions locally without causing its state to become inconsistent. The consistency requirements across the whole file system, however, are much more relaxed. The design is fairly fragile and depends strongly on having well-behaved clients. Before enabling file lock/unlock capabilities, consistency will also depend on luck, as clients maintain no special state that would allow them to consider a file to be open or reserved for their own purposes.
This means that, while a single read or write request should complete correctly once it arrives at the storage server, any other client may interfere between requests. Files currently being accessed by a client may be overwritten by another client, deleted, moved to another storage server, and re-created, all without the client noticing. We should implement a locking capability, the file system will prevent well-behaved clients from performing any such operations until the lock is released.
When implementing the storage and naming servers, we must decide when is the appropriate time for the naming server to command each storage server to create or delete files or directories, thus maintaining the servers' views of the file system in a consistent state. As much as possible, it is preferable to avoid having to rigidly and synchronously maintain all storage servers in the same state. However, the interfaces are highly simplified and do not provide good ways to implement complex schemes for lazy file creation or deletion, so code accordingly. As an example, a file that the naming server has been successfully asked to delete should not remain accessible for subsequent requests to the storage server.
Locking
As part of our DFS implementation, we must create a custom lock type and a particular locking scheme that can be used by well-behaved clients to ensure consistency across multiple requests. Each file and directory may be locked for shared reading or exclusive writing. Multiple clients may lock the same object (file or directory) for reading at the same time, but when a client locks an object for exclusive access, no other client can lock the same object for any kind of access. Shared access permits multiple well-behaved clients to perform operations such as reading files and listing directories simultaneously. Such operations do not interfere with each other; two clients may safely read the same file at the same time. Exclusive access permits well-behaved clients to write to files and modify the directory tree.
When a client requests that any object be locked for any kind of access, all objects along the path to that object, including the root directory, must be locked for shared access. Otherwise, a file that is locked for reading (shared access) could be deleted when another client removes its unlocked parent directory. Be careful about the order in which the FS takes these locks on parent directories. If locks are taken in haphazard order, it is possible to end up with a deadlock where two clients are each holding a lock, and both seek to also take the lock held by the other client in order to proceed.
The locking scheme has a further constraint. Some clients may need to lock multiple objects simultaneously. Doing this in arbitrary order on each client can also result in deadlock for the same reason. Therefore, we require that path objects be comparable. Clients must take locks on path objects according to a total ordering provided by the results of this comparison. This requirement interacts with the requirement to lock sub-directories --- when an object is locked, it is not only the object itself whose lock is taken, but the lock on every object along the path to it. Great care must be taken to ensure that the order defined by the comparison does not lead to deadlocks due to this interaction.
In addition to all of the above, the locks must also provide some measure of fairness. It should not be the case that a client which is waiting for a lock is continuously denied it, and the lock is given to other clients that requested the lock later. This is especially important for clients requesting exclusive access. In the absence of fairness constraints, a large number of readers will make it impossible for any client to write to a file. The writing client will wait for the lock as new readers keep arriving and sharing the lock with current readers.
In order to avoid this, in this project, we'd give the lock to clients on a first-come, first-serve basis. It must never be the case that a client which requests a lock later is granted access before a client which requested earlier, unless both clients are requesting the lock for shared access. In the latter case, however, if two clients are requesting the lock for shared access, and there are no intervening waiting clients, both clients must be able to take the lock at the same time.
Replication
The final version of the project must support replication according to the following simple policy. During a series of read requests, the file is replicated once for every 20 read requests, provided there are enough storage servers connected to the naming server to maintain additional copies. At a write request, the naming server selects one storage server to keep a copy of the file, and all other copies are invalidated (removed) before the remaining copy is updated.
Since the naming server has no way of directly tracking read and write requests, or the amount of traffic associated with each file, it makes the simplifying assumption to count shared locks in place of read requests and exclusive locks in place of write requests.
Be careful about how replication interacts with locking. Well-behaved clients should not be able to interfere with the replication operation and cause the results to become inconsistent. Well-behaved clients should, however, be able to read from existing copies of a file, even as a new copy is being created.
APIs
In the API documentation included in the starter code repository, there are several APIs that yield JSON responses like:
{
"exception type": "FileNotFoundException",
"exception info": "File/path cannot be found."
}
Because all the communication data is converted to JSON in our system, there is a potential problem for read() and write(), where we must send a byte array to the server, but JSON doesn't support byte[]. We will use base64 encoding/decoding to solve this problem.
Potential Failure Scenarios
Network Partitions
In a distributed system, network partitions are inevitable and may lead to potential failures. If a partition separates the leader from the majority of the nodes, a new leader will be elected in the majority partition. However, the old leader, unaware of this change, may continue to service client requests. While Raft ensures that these changes won't be committed (since they lack the majority approval), it may result in inconsistencies from a client's perspective, as their changes might be later overwritten.
High Load and Resource Exhaustion
Our system might encounter scenarios where the incoming request rate surpasses the processing capabilities of the nodes. This could result in severe latency issues, potential loss of client requests, or even crash due to resource exhaustion. Although our implementation ensures data consistency under normal operation, it does not yet offer a sophisticated load-balancing mechanism or rate limiting to prevent such scenarios.
Unbounded Log Growth
As our implementation does not include log compaction or snapshots, the log size could grow indefinitely over time, leading to performance degradation and increased resource usage. While this is not necessarily a failure scenario, it is a limitation of our current implementation that could impact its performance and usability in long-running systems.
Summary
Implementing a distributed system based on the Raft consensus algorithm has not been without its share of challenges. To start with, achieving consensus in a distributed network, especially in the face of network partitions and message loss, is a complex task. Balancing the competing needs of consistency and availability, while also ensuring partition tolerance, has required careful system design and thorough testing.
Furthermore, despite the simplicity of Raft compared to other consensus algorithms, the implementation still requires a deep understanding of distributed system principles. One such challenge is ensuring log replication across all nodes in the face of failures and restarts. Managing the persistent state on all servers in an efficient manner, and implementing the leader election and the log replication process according to the rules of Raft, demanded meticulous attention to detail.
Java, while a robust language, introduced its own set of complexities, particularly in handling concurrent operations and managing state across different threads. In spite of its rich library support and powerful concurrency primitives, the complexity of managing multi-threading and synchronization in a distributed environment posed significant challenges.
Looking forward, there are several areas we believe could benefit from further exploration and enhancement. For instance, implementing more sophisticated membership change protocols could allow for more dynamic and flexible cluster scaling. Additionally, exploring ways to improve system performance under high loads, possibly through more advanced load-balancing strategies or efficient resource management, could prove beneficial.
Another promising avenue is to further improve fault tolerance and data redundancy strategies, which could include more advanced snapshotting techniques or erasure coding schemes. Finally, enhancing the security aspects of the system, like implementing client-server and server-server authentication and encryption, could add an additional layer of protection to the distributed file system.
Implementing a Raft-based distributed file system has been a complex, yet rewarding task. The potential future enhancements speak to the richness and depth of distributed systems as a field, and we look forward to continuing to improve upon our implementation.
Reference
- [1] HashiCorp, “You. Must. Build. A. Raft! Consul’s Consensus Protocol Explained,” HashiCorp, 2019. https://www.hashicorp.com/resources/raft-consul-consensus-protocol-explained.